La amenaza de los deepfakes de voz: guía completa 2025
Todo sobre los deepfakes de voz: cómo funcionan, casos reales de fraude, cómo detectarlos y cómo proteger tu empresa. Guía actualizada 2025.
Phonomica
Equipo de contenido
20 de febrero de 2024
Actualizado: 15 de enero de 2025
La amenaza de los deepfakes de voz: guía completa 2025
Tiempo de lectura: 12 minutos
Última actualización: Enero 2025
En enero de 2020, un banco en Hong Kong transfirió $35 millones después de una llamada telefónica. La voz del otro lado sonaba exactamente como el director de la empresa matriz. Era un deepfake.
Cuatro años después, crear esa voz falsa ya no cuesta miles de dólares ni requiere expertise técnico. Con $5 al mes y 3 segundos de audio, cualquiera puede clonar una voz.
Esta guía explica qué son los deepfakes de voz, cómo funcionan, los casos reales de fraude, y—lo más importante—cómo protegerte.
Tabla de contenidos
- ¿Qué son los deepfakes de voz?
- Cómo se crea un deepfake de voz
- El crecimiento alarmante
- Casos reales de fraude
- Tipos de ataques
- ¿Podemos detectarlos?
- Anti-spoofing: La defensa
- Recomendaciones para empresas
- El futuro de esta carrera armamentista
¿Qué son los deepfakes de voz?
Un deepfake de voz es audio generado artificialmente que imita la voz de una persona específica. Usando inteligencia artificial, es posible crear grabaciones de alguien diciendo algo que nunca dijo.
El término “deepfake” combina “deep learning” (aprendizaje profundo) con “fake” (falso). Aunque el término se popularizó con videos manipulados, los deepfakes de audio son técnicamente más fáciles de crear y, en muchos contextos, más peligrosos.
¿Por qué son peligrosos los deepfakes de voz?
1. Son convincentes. Las herramientas modernas generan audio que es prácticamente indistinguible del real para oídos humanos.
2. Son baratos. Lo que antes costaba miles de dólares, hoy cuesta $5-20 al mes.
3. Son rápidos. Segundos de audio de referencia son suficientes para clonar una voz.
4. Son remotos. A diferencia de un deepfake visual (que requiere video), un deepfake de voz puede usarse en una llamada telefónica donde no hay forma visual de verificar.
5. Explotan la confianza. “Reconozco la voz de mi jefe” ya no es una verificación válida.
Cómo se crea un deepfake de voz
El proceso de crear un deepfake de voz se ha simplificado dramáticamente. Así funciona:
El proceso básico
1. Recolectar audio de la víctima
2. Entrenar/adaptar modelo de clonación
3. Generar audio con cualquier texto
4. Usar para fraudePaso 1: Recolectar audio
El atacante necesita audio de la víctima. Las fuentes son abundantes:
- Redes sociales: Videos de Instagram, TikTok, YouTube
- Podcasts y entrevistas: Ejecutivos frecuentemente aparecen en medios
- Grabaciones de llamadas: Call centers graban llamadas que pueden ser brecheadas
- Voicemails: Mensajes de voz accesibles
- Videos corporativos: Presentaciones, webinars
Un CEO promedio tiene horas de audio público disponible. Un estudio de McAfee encontró que el 53% de los adultos comparte su voz online al menos una vez por semana.
Paso 2: Entrenar el modelo
Antes (2019-2021):
- Se necesitaban 30-60 minutos de audio limpio
- Hardware con GPU potente ($2,000+)
- Conocimiento técnico de ML
- Horas de entrenamiento
Ahora (2024):
- 3-30 segundos de audio
- Una cuenta en un servicio SaaS ($5-20/mes)
- Cero conocimiento técnico
- Segundos de procesamiento
Paso 3: Generar audio
El atacante escribe el texto que quiere que “diga” la víctima. El modelo genera audio con la voz clonada.
Ejemplo de interfaz (ElevenLabs):
Voz: [CEO clonado]
Texto: "Hola María, soy Roberto. Necesito que hagas una
transferencia urgente de $50,000 a esta cuenta.
Es confidencial, no lo comentes con nadie."
[Generar]En segundos, tenés un audio convincente.
Paso 4: Ejecutar el fraude
El audio puede usarse de varias formas:
- Llamada telefónica pregrabada
- Mensaje de voz
- En tiempo real (con herramientas modernas)
El crecimiento alarmante
Evolución de las herramientas
| Año | Herramientas disponibles | Audio requerido | Costo típico |
|---|---|---|---|
| 2019 | <5, técnicas | 30+ minutos | $500+ |
| 2020 | ~10, mix técnico/SaaS | 10-30 minutos | $100-300 |
| 2021 | ~15, mayoría SaaS | 5-10 minutos | $50-100 |
| 2022 | 20+, todas SaaS | 1-5 minutos | $20-50 |
| 2023 | 30+, open source maduro | 10-60 segundos | $5-30 |
| 2024 | 50+, real-time disponible | 3-10 segundos | $0-20 |

Estadísticas de ataques
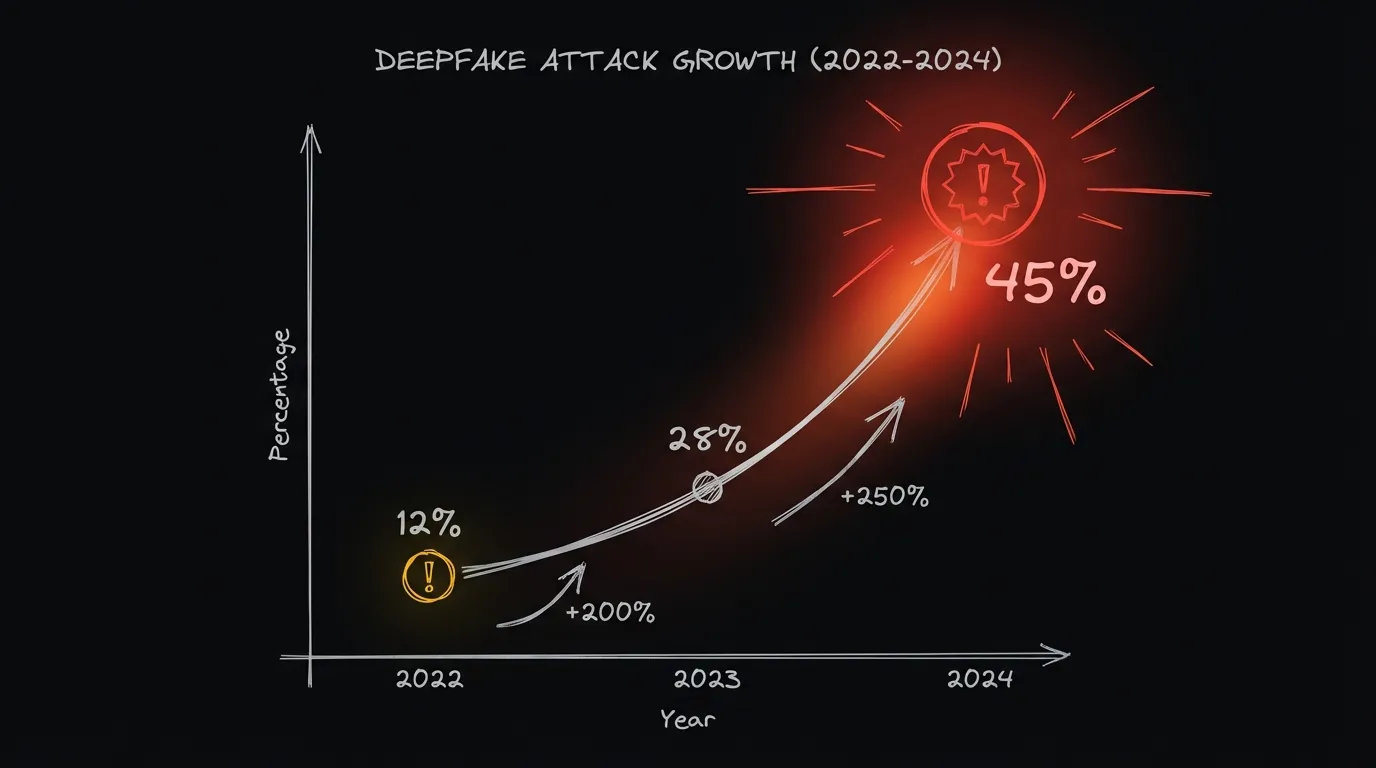
Los datos de la industria muestran un crecimiento exponencial:
- 2022: Ataques de deepfake de voz representaban ~12% de los intentos de fraude sofisticado
- 2023: Aumentaron a ~28%
- 2024: Representan ~45% de los ataques sofisticados
El incremento año a año:
- 2022 → 2023: +200%
- 2023 → 2024: +250%
Por qué el crecimiento es tan rápido
1. Democratización de la tecnología
Microsoft publicó VALL-E en enero 2023, demostrando clonación con 3 segundos de audio. Aunque no liberaron el modelo, la investigación permitió a otros replicar los resultados.
2. Modelos open source de alta calidad
Herramientas como RVC (Retrieval-based Voice Conversion), OpenVoice, y XTTS son gratuitas, open source, y de calidad comparable a las comerciales.
3. Bajo riesgo percibido
Los atacantes perciben (correctamente, en muchos casos) que las defensas son débiles y que el fraude por voz es difícil de rastrear.
4. Alto retorno
Un solo ataque exitoso puede generar pérdidas de millones. El ROI para el atacante es enorme.
Casos reales de fraude
Caso 1: CEO Fraud UK - $243,000 (2019)
Contexto: El CEO de una empresa energética del Reino Unido recibió una llamada de quien creía era su jefe, el CEO de la empresa matriz alemana.
El ataque: La voz (deepfake) instruyó una transferencia urgente de €220,000 a un proveedor en Hungría. El CEO británico reconoció la voz, el acento alemán, y el patrón de habla de su jefe.
Resultado: El dinero fue transferido y nunca recuperado.
Lección: “Reconozco la voz” ya no es verificación suficiente.
Caso 2: Hong Kong - $35 millones (2020)
Contexto: Un empleado de un banco en Hong Kong recibió instrucciones de transferir fondos de quien creía era el director de una empresa cliente.
El ataque: Deepfake de voz coordinado con emails falsificados que daban contexto y legitimidad. Las instrucciones fueron para múltiples transferencias a cuentas en varios países.
Resultado: $35 millones perdidos antes de que se detectara la irregularidad en auditoría.
Lección: Los ataques de deepfake son más efectivos cuando se combinan con otros vectores (phishing, documentos falsos).
Caso 3: Extorsión masiva en México (2024)
Contexto: Cientos de familias en México recibieron llamadas de supuestos secuestradores con la voz de sus familiares.
El ataque: Los atacantes usaron audio de TikTok e Instagram para clonar voces de jóvenes. Luego llamaron a los padres simulando un secuestro con la voz del hijo/a pidiendo dinero.
Resultado: Estimado $5 millones en pagos antes de campañas de concientización.
Lección: Cualquier persona con presencia en redes sociales puede ser víctima de clonación.
Caso 4: Contact center Latinoamérica (2024)
Contexto: Un contact center de servicios financieros detectó un patrón inusual de llamadas.
El ataque: Atacantes usaban voice conversion en tiempo real durante llamadas para hacerse pasar por clientes. Pasaban la autenticación tradicional (preguntas de seguridad) y solicitaban operaciones fraudulentas.
Resultado: Detectado por sistema anti-spoofing antes de pérdidas significativas.
Lección: La defensa tecnológica es efectiva cuando está implementada.
Tipos de ataques
No todos los ataques de manipulación de voz son iguales. Entender los tipos ayuda a defenderse mejor:
1. Replay Attack (más común)
Qué es: Reproducir una grabación real de la víctima.
Cómo funciona: El atacante obtiene una grabación de la víctima (de una llamada anterior, un voicemail, etc.) y la reproduce durante la autenticación.
Prevalencia: ~40% de los ataques
Detección: Relativamente fácil. Los sistemas detectan artefactos de reproducción, falta de naturalidad, y diferencias de canal.
2. Deepfake / Síntesis TTS
Qué es: Generar audio completamente nuevo con IA que suena como la víctima.
Cómo funciona: Se entrena o adapta un modelo con audio de la víctima, y luego se genera cualquier texto con esa voz.
Prevalencia: ~35% de los ataques, creciendo rápido
Detección: Más difícil. Requiere detectar artefactos sutiles de síntesis.
3. Voice Conversion
Qué es: El atacante habla, pero su voz se transforma en tiempo real para sonar como la víctima.
Cómo funciona: Un modelo convierte las características de una voz a otra mientras preserva el contenido.
Prevalencia: ~20% de los ataques, creciendo muy rápido
Detección: Desafiante. El audio tiene características de voz real (respiración, pausas naturales) pero también artefactos de conversión.
4. Audio Editado / Splicing
Qué es: Combinar fragmentos de audio real para crear mensajes nuevos.
Cómo funciona: Extraer palabras/frases de grabaciones reales y concatenarlas.
Prevalencia: ~5% de los ataques
Detección: Moderadamente fácil. Las transiciones entre fragmentos suelen ser detectables.
Comparativa
| Tipo | Sofisticación | Costo | Tiempo real posible | Detección |
|---|---|---|---|---|
| Replay | Baja | Muy bajo | No | Fácil |
| Deepfake | Media | Bajo | Sí (2024) | Media |
| Voice conversion | Alta | Bajo | Sí | Difícil |
| Audio editado | Baja | Muy bajo | No | Fácil |

¿Podemos detectarlos?
Sí, pero con matices importantes.
¿Pueden los humanos detectar deepfakes?
Respuesta corta: No confiablemente.
Estudios muestran que los humanos detectan deepfakes de voz de alta calidad con una tasa apenas mejor que el azar (~55% de precisión). Los deepfakes modernos son simplemente demasiado buenos.
¿Pueden las máquinas detectar deepfakes?
Respuesta corta: Sí, con alta efectividad cuando los sistemas están actualizados.
Los sistemas de anti-spoofing basados en deep learning alcanzan:
- >95% de detección para herramientas conocidas
- 80-90% de detección para herramientas nuevas (antes de actualización)
- <3% de falsos positivos (audio real marcado como falso)
Por qué la detección es posible
Aunque los deepfakes suenan convincentes para humanos, dejan “huellas” detectables:
1. Artefactos de vocoder Los generadores de audio usan “vocoders” (voice coders) que introducen patrones sutiles en el espectro de frecuencias.
2. Falta de variabilidad natural La respiración, pausas, micro-variaciones de tono en voz real tienen patrones que la síntesis no replica perfectamente.
3. Inconsistencias acústicas El ambiente, la reverberación, las características del micrófono dejan huellas que la síntesis no captura.
4. Patrones de la herramienta Cada herramienta de síntesis deja su propia “firma”. ElevenLabs suena diferente a OpenVoice a nivel espectral.
Anti-spoofing: La defensa
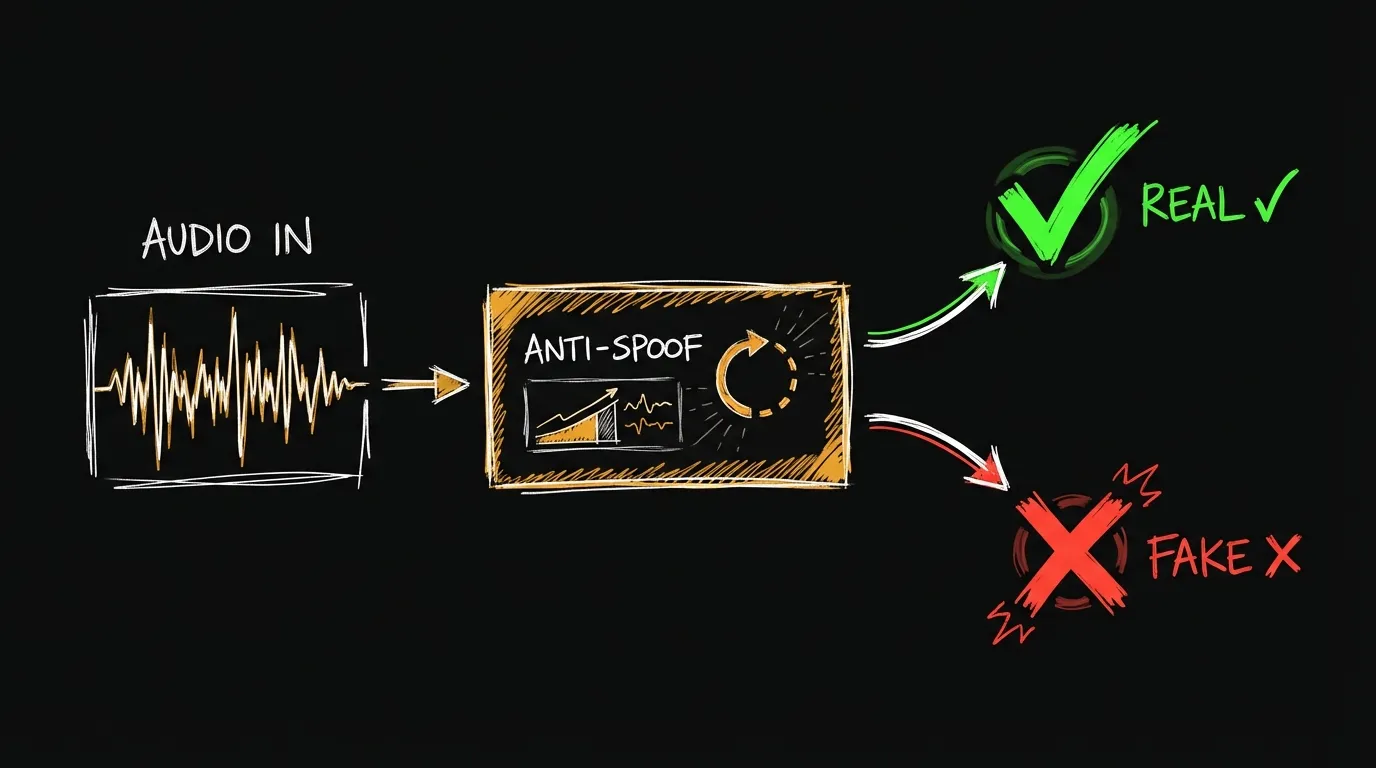
El anti-spoofing (también llamado liveness detection o presentation attack detection) es la tecnología que detecta audio manipulado.
Cómo funciona
Un sistema anti-spoofing típico:
Audio entrante → Extracción de features → Modelo de clasificación → Decisión (real/fake)Los modelos analizan características que distinguen audio real de manipulado:
- Espectrogramas
- Features de bajo nivel (pitch, jitter, shimmer)
- Patrones temporales
- Anomalías estadísticas
Modelos de referencia
| Modelo | Técnica | EER en ASVspoof |
|---|---|---|
| AASIST | Attention + spectro-temporal | <1% |
| RawNet2 | Raw audio end-to-end | ~1.5% |
| LCNN | Light CNN | ~2% |
| Wav2vec-based | Transfer learning | ~1% |
El desafío de la generalización
El problema principal del anti-spoofing es que los modelos funcionan muy bien para ataques que han visto, pero pueden fallar con ataques nuevos.
Solución: Anti-spoofing adaptativo
- Monitorear herramientas de síntesis emergentes
- Generar ejemplos de cada herramienta nueva
- Re-entrenar o adaptar modelos
- Deploy rápido (horas, no meses)
En Phonomica, monitoreamos continuamente el ecosistema de herramientas de síntesis y actualizamos nuestros modelos de detección semanalmente.
Defensa en profundidad
El anti-spoofing de audio no debería ser la única línea de defensa. Un approach multicapa incluye:
Capa 1: Audio anti-spoofing
- Detectar manipulación en el audio
Capa 2: Behavioral biometrics
- Analizar patrones de habla, velocidad, pausas
- Comparar con comportamiento histórico
Capa 3: Señales contextuales
- Device fingerprint
- Geolocalización
- Hora del día
- Historial de transacciones
Capa 4: Monitoreo de transacciones
- Detectar montos, destinos, patrones inusuales
Recomendaciones para empresas
Si tu empresa usa o considera usar autenticación por voz, o simplemente quiere protegerse contra fraude por deepfake:
Recomendaciones inmediatas
1. Eliminar la autenticación basada solo en “reconocer la voz”
Si tus empleados aprueban transacciones porque “reconocen la voz del jefe”, esto debe cambiar inmediatamente. Implementar callbacks a números verificados, códigos de confirmación, o autenticación multi-persona.
2. Concientizar a empleados sobre deepfakes
Entrenar a empleados, especialmente en finanzas y atención al cliente, sobre la existencia y riesgo de deepfakes. El mensaje: “No confíes solo en la voz.”
3. Establecer protocolos para transacciones sensibles
Para transferencias grandes o cambios críticos:
- Múltiples aprobadores
- Callback a número conocido (no el que llama)
- Verificación fuera de banda (email + llamada + código)
Recomendaciones a mediano plazo
4. Implementar biometría de voz con anti-spoofing
Si usás autenticación por voz, asegurate de que incluya detección de deepfakes actualizada. Un sistema de biometría de voz SIN anti-spoofing es un riesgo, no una protección.
5. Considerar defensa multicapa
No depender solo de un método de verificación. Combinar:
- Biometría de voz
- Autenticación de dispositivo
- Análisis de comportamiento
- Verificación de transacción
6. Auditar grabaciones de llamadas
Si tu empresa graba llamadas, evaluar:
- ¿Dónde se almacenan?
- ¿Quién tiene acceso?
- ¿Podrían ser usadas para entrenar deepfakes?
Recomendaciones a largo plazo
7. Monitorear el panorama de amenazas
Las herramientas de deepfake evolucionan constantemente. Mantenerse informado sobre nuevas técnicas y ajustar defensas.
8. Preparar respuesta a incidentes
¿Qué hacer si descubrís que tu empresa fue víctima de fraude por deepfake?
- Protocolo de comunicación
- Proceso de investigación
- Contacto con autoridades
9. Considerar seguros cyber
Evaluar pólizas de cyber insurance que cubran fraude por deepfake. Cada vez más aseguradoras preguntan específicamente por controles contra este tipo de ataque.
El futuro de esta carrera armamentista
Hacia dónde van los deepfakes
Real-time ya es realidad En 2024, herramientas como RVC permiten voice conversion en tiempo real con latencia <200ms. Esto significa que durante una llamada, alguien puede hablar con tu voz.
Calidad seguirá mejorando VALL-E 2 y modelos similares están cerrando la brecha con audio real. En condiciones ideales, la diferencia ya es casi indetectable.
Multimodal es lo próximo Video + audio sincronizados. Videollamadas completamente falsas serán posibles en 2025-2026.
Hacia dónde va la defensa
Detección adaptativa Modelos que se actualizan continuamente, casi en tiempo real, para detectar nuevas herramientas de síntesis.
Defensa multicapa Combinación de audio, behavioral, contextual, y transaccional para decisiones más robustas.
Watermarking Marcar audio legítimo de forma que sea verificable. Iniciativas como C2PA están trabajando en estándares.
Regulación Leyes específicas contra deepfakes maliciosos están emergiendo. México, EU, y varios países de LATAM tienen legislación en proceso.
¿Quién va a ganar?
Es una carrera armamentista sin fin claro. Pero hay razones para optimismo:
-
La defensa puede ser proactiva. Los defensores pueden estudiar herramientas de ataque y prepararse antes de que se usen maliciosamente.
-
Los atacantes necesitan más que solo un deepfake. Un deepfake convincente es solo parte del ataque. La defensa multicapa dificulta el resto.
-
El costo de la defensa escala mejor. Un sistema de detección puede proteger millones de transacciones. Un atacante necesita esfuerzo por cada ataque.
Conclusión
Los deepfakes de voz son una amenaza real, presente, y creciente. Las herramientas para crearlos son accesibles para cualquiera. Los casos de fraude multimillonarios ya no son excepciones.
Pero la defensa también existe. Los sistemas anti-spoofing modernos detectan la gran mayoría de los ataques. La defensa multicapa hace que los ataques exitosos sean difíciles y costosos para los atacantes.
La pregunta no es si tu empresa debería prepararse, sino cuándo. Cada mes de espera es un mes de exposición a un riesgo que está creciendo exponencialmente.
Próximos pasos
¿Querés evaluar tu vulnerabilidad a deepfakes?
Solicitar evaluación de riesgos →
¿Querés ver detección de deepfakes en acción?
¿Querés conocer el pricing?
Recursos relacionados
- Cómo funciona la biometría de voz: Guía completa
- 5 tipos de ataques a sistemas de biometría de voz
- El caso CEO Fraud UK: Lecciones de $243K perdidos
- ¿Puede ElevenLabs engañar a un sistema de biometría?
Este artículo se actualiza regularmente para reflejar el estado actual de las amenazas. Última actualización: Enero 2025.
Artículos relacionados
El caso CEO Fraud UK: lecciones de $243K perdidos por deepfake de voz
Análisis del caso CEO Fraud UK de 2019: cómo un deepfake de voz costó $243K a una empresa energética y qué lecciones podemos aprender.
Artículo¿Puede ElevenLabs engañar a un sistema de biometría de voz?
Probamos ElevenLabs contra sistemas de biometría de voz. ¿Puede la clonación de voz más popular engañar a la autenticación biométrica?
Caso de estudioCaso de estudio: banco argentino evoluciona de agente humano a voicebot a biometría de voz
Análisis comparativo de tres modelos de autenticación en un banco argentino: agente humano, voicebot con TTS, y biometría de voz. Costos, tiempos y ROI.
¿Querés implementar biometría de voz?
Agendá una demo y descubrí cómo Phonomica puede ayudarte.